WebScrapping using BeautifulSoup library, then storing the data in MongoDB

Search for a command to run...
No comments yet. Be the first to comment.
📑 Table of Contents Introduction Why Use kubeadm System Requirements Cluster Architecture Overview Networking Requirements Why Disable Swap Understanding Cgroups and Drivers Step-by-Step Setu

Jenkins is an essential tool for automating software builds, deployments, and CI/CD pipelines. If you're running Jenkins on an AWS EC2 instance, exposing it securely over the internet is crucial. By default, Jenkins runs on port 8080 over HTTP, which...
Introduction Cloud computing is being adopted vastly by more than 90 percent of the fortune 500 companies with Amazon Web Services (AWS) getting a large slice of the pie while it continues on it's quest for world domination in the cloud computing spa...

Guide on how to create a Python monitoring application using Flask, containerize it using Docker, and deploy it to kubernetes.

Web scraping is the process of extracting data from websites, which can be a very useful technique for obtaining large amounts of data quickly and efficiently. In this blog, we will explore how to write a web scraper in Python using the requests and BeautifulSoup libraries, and how to save the results in MongoDB using the pymongo library. Mongo Express will also be connected to MongoDB to have visuals of the database. MongoDB and Mongo Express will be set up using Docker.
Before we begin, it's important to understand the legal and ethical considerations when web scraping. Be sure to check the website's terms of service to ensure that web scraping is allowed, and be respectful of the website's resources and bandwidth by not overloading their server with requests. Additionally, some websites may have anti-scraping measures in place, so proceed with caution and avoid any actions that may be seen as malicious or harmful.
You can check by inspecting the robots.txt file of the website 'https://example.com/robots.txt'
Now, let's dive into the code.
Let's walk through the process of setting up MongoDB and Mongo Express using Docker.
Before we begin, you will need to have Docker installed on your machine. You can download and install Docker from the official website: https://www.docker.com/products/docker-desktop.
First, let's create a Docker Network which will be used by both MongoDB and Mongo Express to enable communication between them. Then we test to see if the network has been created successfully.
docker network create mongo-network
docker network ls
Next, let's create a Docker container for MongoDB. To do this, we can run the following command:
docker run -d --name mongodb --network mongo-network -p 27017:27017 mongo
This command will download the latest MongoDB image from Docker Hub and start a container named 'mongo' while a network is connected to it. We are also mapping port 27017 from the container to port 27017 on our host machine.
You can verify that the container is running by running the command:
docker ps
This should list all running containers, and you should see the 'mongo' container listed.
docker run -d \
--network mongo-network \
--name mongo-express \
-p 8081:8081 \
-e ME_CONFIG_MONGODB_SERVER="mongodb" \
-e ME_CONFIG_BASICAUTH_USERNAME="admin" \
-e ME_CONFIG_BASICAUTH_PASSWORD="1234567890" \
mongo-express
This command will download the latest Mongo Express image from Docker Hub and start a container named 'mongo-express'. We are also mapping port 8081 from the container to port 8081 on our host machine.
The environment variables ME_CONFIG_MONGODB_SERVER, ME_CONFIG_BASICAUTH_USERNAME, and ME_CONFIG_BASICAUTH_PASSWORD are used to configure Mongo Express to connect to our MongoDB container and set up basic authentication.
Once the container is running, you can access Mongo Express by opening a web browser and navigating to http://localhost:8081. You should see a login screen where you can enter the username and password you set up in the previous step.
After logging in, you should see a dashboard where you can view and manage your MongoDB databases.
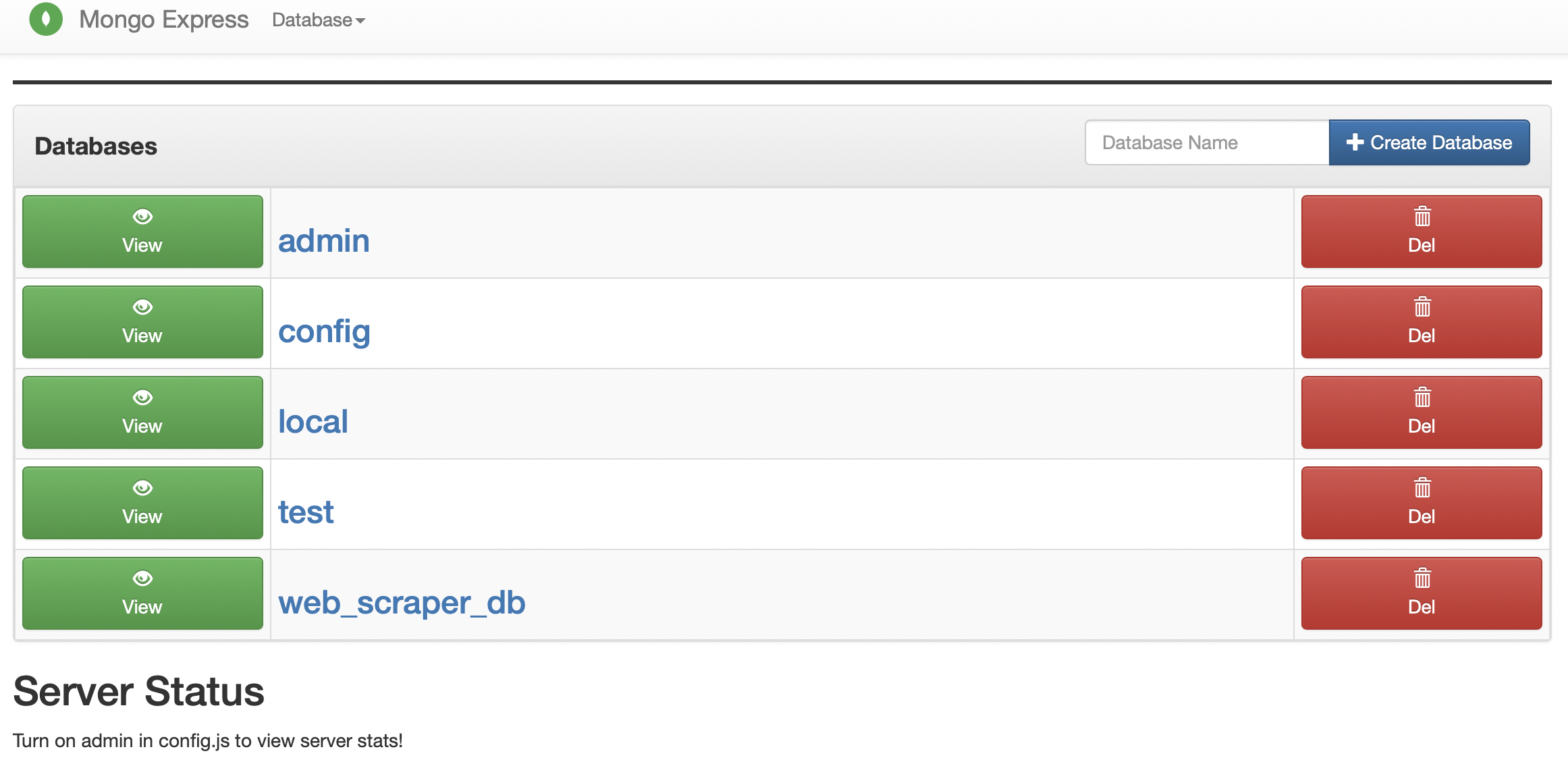
We have three options to create a database. First, you can create it from the mongo-express UI by simply clicking 'create database'. Secondly, you can write python code. Thirdly, you can create it on the command line or terminal with the following commands:
docker exec -it mongodb mongosh
The above command is used to interactively login into the MongoDB container. The command mongosh is the mongo interactive shell.
Next, we will create a DataBase and a Collection where our data will be stored, using the following commands:
#create a database named web_scraper_db.
use web_scraper_db
#create new user
db.createUser({ user: "User1", pwd: "1234567890", roles: [{ role: "readWrite", db: "web_scraper_db" }] })
#create a collection named web_scraper_collection.
db.createCollection('web_scraper_collection')
#add a document in the web_scraper_collection colection.
db.web_scraper_collection.insert({item: "apple", cost: 3})
#add a document in the web_scraper_collection colection.
db.web_scraper_collection.insert({item: "pear", qty: 5})
#select documents in the web_scraper_collection collection. It should display the two created documents with the _id property.
db.web_scraper_collection.find():
show users #list all users.
exit #exit.
#log back into mongo container with a specific user
docker exec -it mongodb mongosh --username User1 --password 1234567890 --authenticationDatabase web_scraper_db
#check the current user.
db.runCommand({connectionStatus : 1})
#confirm if User1 can query documents.
db.web_scraper_collection.find()
exit #exit the mongodb shell.
You can check out mongodb.com for additional info on more MongoDB commands.
Next step we write some python code to bring our idea to life.
The first step is to import the necessary libraries. In this case, we will need requests, BeautifulSoup, and pymongo
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
Next, we need to set up a connection to the MongoDB database where we will be storing our scraped data. We will use the MongoClient class to connect to the database and create a collection to store our data.
MONGO_DB_URL = 'mongodb://User1:1234567890@localhost:27017/web_scraper_db'
client = MongoClient(MONGO_DB_URL)
db = client['web_scraper_db']
collection = db['web_scraper_collection']
Here, we are connecting to a local MongoDB instance with the URL 'mongodb://User1:1234567890@localhost:27017/web_scraper_db' You will need to modify this URL to match your own MongoDB instance. We are then creating a database called web_scraper_db and a collection called web_scraper_collection
Now that we have our MongoDB connection set up, we can begin scraping the website. In this example, we will be scraping the website https://books.toscrape.com/ to extract information about books.
URL = 'https://books.toscrape.com/'
response = requests.get(URL)
soup = BeautifulSoup(response.content, 'html.parser')
Here, we are using the requests library to send a GET request to the website and retrieve the HTML content. We then use BeautifulSoup to parse the HTML content and create a BeautifulSoup object that we can use to extract information.
books = soup.find_all('article', class_='product_pod')
book_list = []
for book in books:
title = book.h3.a.attrs['title']
link = book.h3.a.attrs['href']
price = book.select_one('p.price_color').get_text()
book_list.append({'title': title, 'link': link, 'price': price})
In this section of the code, we are using BeautifulSoup to extract information about the books on the website. We are searching for all HTML elements with the tag 'article' and the class 'product_pod', which represents the individual books on the website. We then iterate over each book and extract the title, link, and price information. We store this information in a list of dictionaries called book_list.
Now that we have our data in the book_list variable, we can insert it into our MongoDB collection.
collection.insert_many(book_list)
Here, we are using the insert_many method to insert all the books in the book_list variable into the MongoDB collection.
num_books = collection.count_documents({})
print(f"Total number of books in the collection: {num_books}")
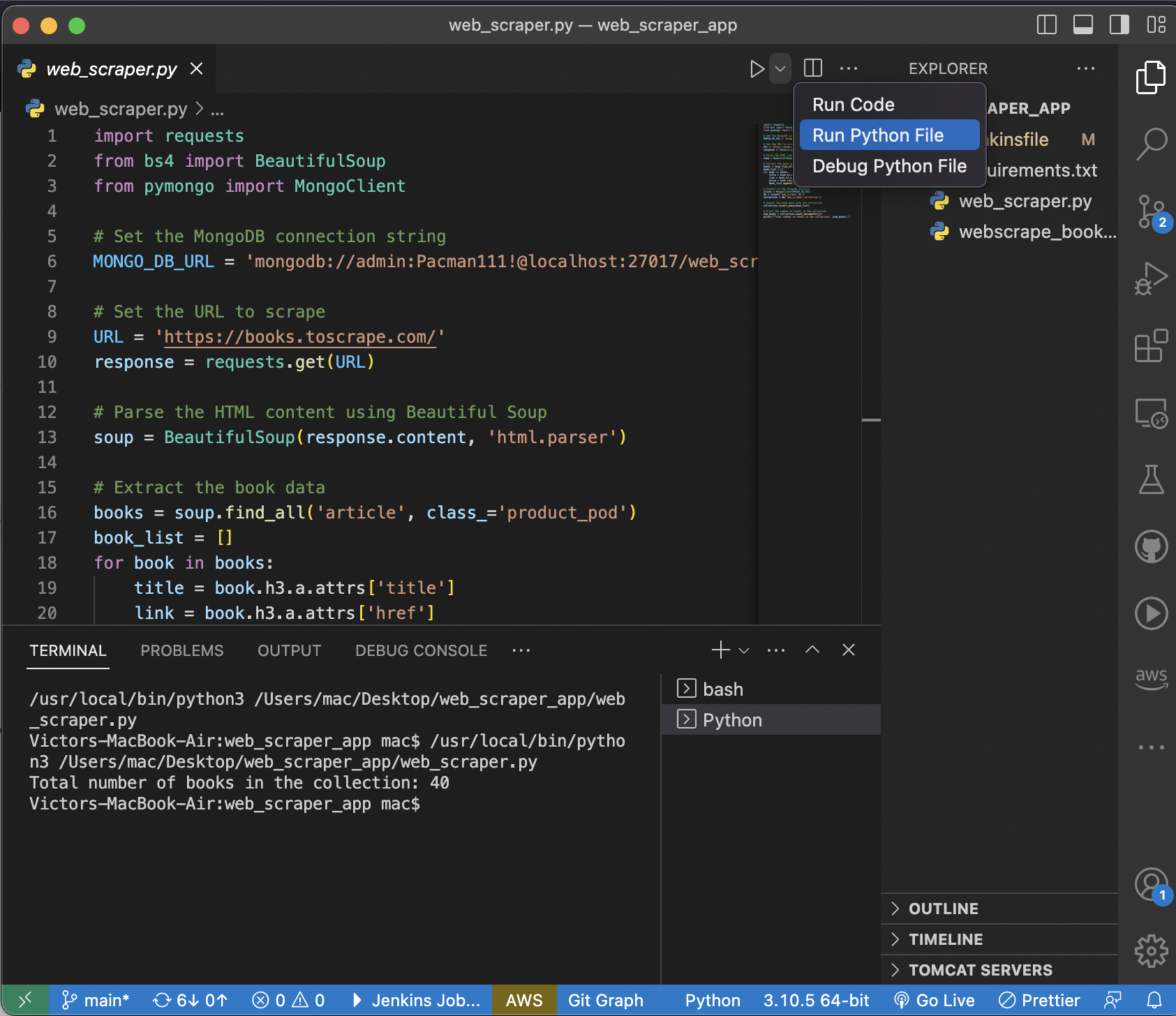
Save the python codes in a file web_scrapper.py You can run the python script to execute the commands. All things being equal you should get the results below:
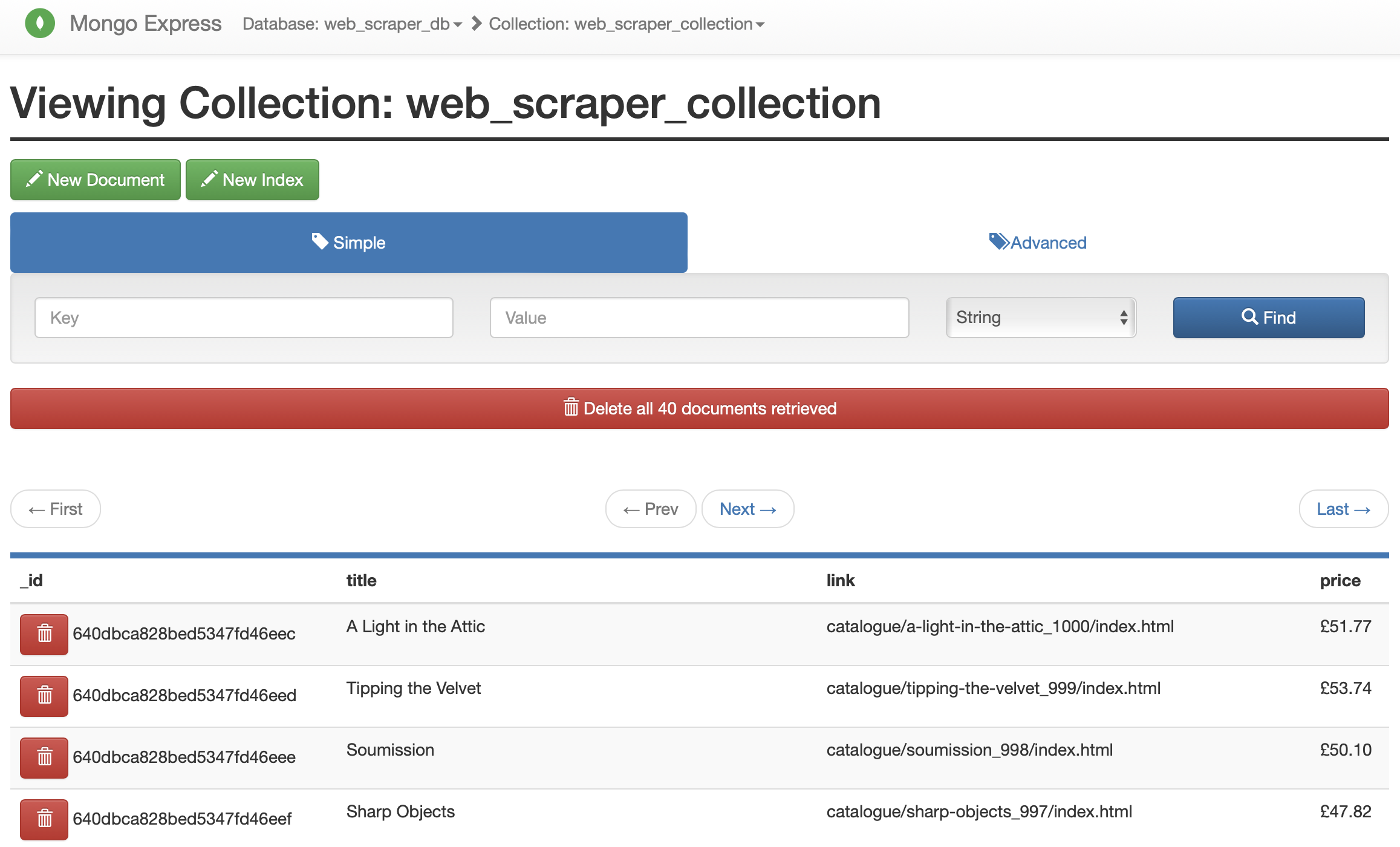
Next, let's log in to mongo express using the URL http://localhost:8081 Once logged in click the database created earlier, then click the collection we created which will lead to a page where we can visualize the data scrapped from 'https://books.toscrape.com/'
You can log into the MongoDB container created earlier to query the database with the commands I provided earlier to see the data we saved in it.
docker exec -it mongodb mongosh
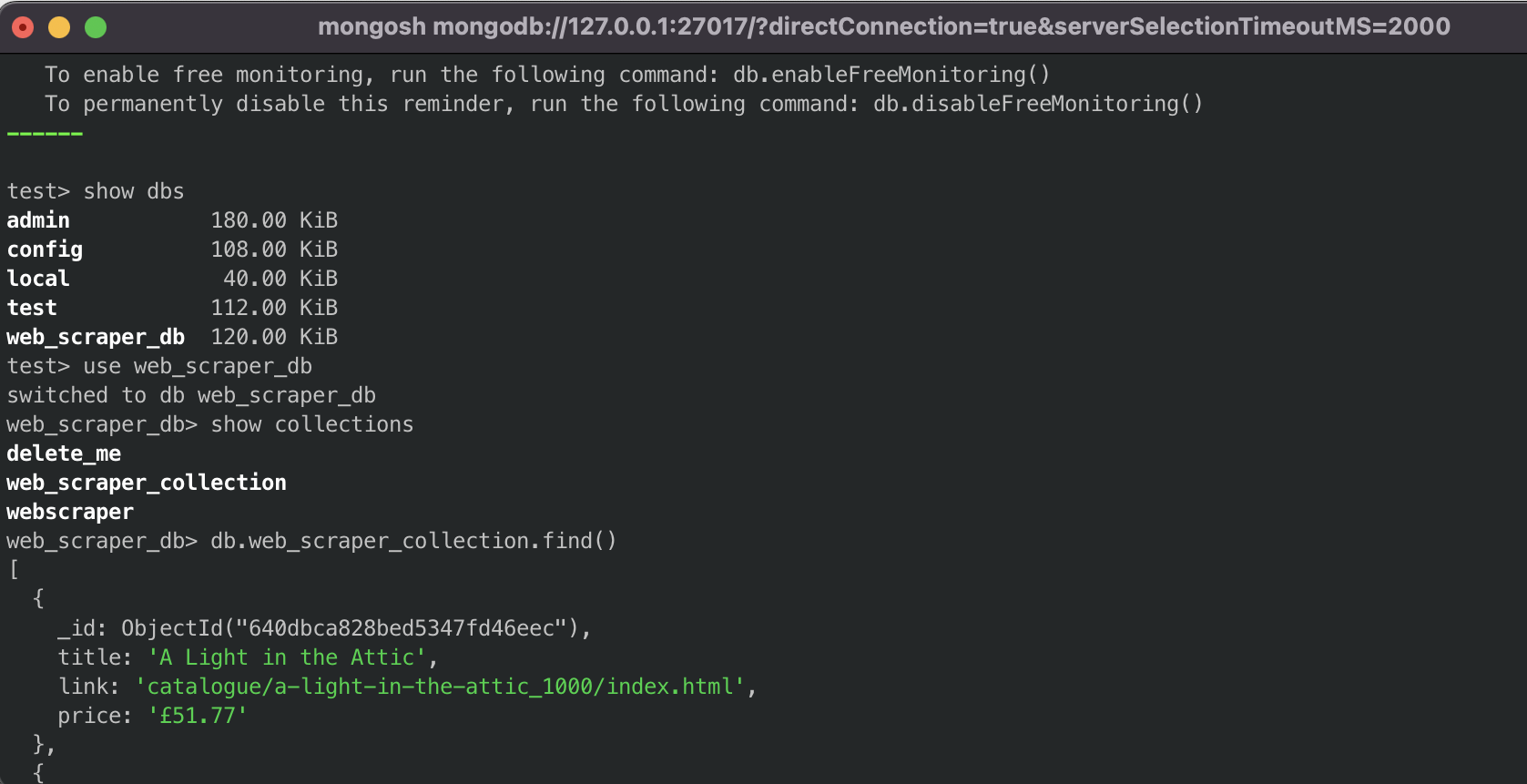
#mongodb commands to view web scrape data
show dbs
use web_scraper_db
show collections
db.web_scraper_collection.find()
You should get the results below
Conclusion
In this blog, we have covered how to set up MongoDB and Mongo Express using Docker, allowing us to easily create and manage MongoDB databases and access a visual interface for managing our data. Then we wrote a python code to run the command to web scrape the website. With these tools, we can easily create web scrapers like the one we discussed earlier and store the data in our MongoDB databases.
Hope you enjoyed this TUTORIAL !!! Good Luck and Happy coding !!!